How to Read a Parquet File From S3 Using Python
Python and Parquet Performance
In Pandas, PyArrow, fastparquet, AWS Data Wrangler, PySpark and Dask
![]()
This mail service outlines how to employ all mutual Python libraries to read and write Parquet format while taking advantage of columnar storage , columnar compression and data partitioning . Used together, these iii optimizations can dramatically accelerate I/O for your Python applications compared to CSV, JSON, HDF or other row-based formats. Parquet makes applications possible that are simply impossible using a text format like JSON or CSV.
Annotation: this post was written in October of 2020. It will fall out of date unless yous betoken out bugs with comments. Thanks!
Introduction
I take recently gotten more than familiar with how to work with Parquet datasets across the half dozen major tools used to read and write from Parquet in the Python ecosystem: Pandas, PyArrow, fastparquet, AWS Information Wrangler, PySpark and Dask. My work of late in algorithmic trading involves switching between these tools a lot and as I said I often mix up the APIs. I use Pandas and PyArrow for in-RAM computing and machine learning, PySpark for ETL, Dask for parallel calculating with numpy.arrays and AWS Information Wrangler with Pandas and Amazon S3. I've used fastparquet with pandas when its PyArrow engine has a problem, but this was my first fourth dimension using it straight.
The very first thing I do when I piece of work with a new columnar dataset of any size is to convert information technology to Parquet format… and nevertheless I constantly forget the APIs for doing and then as I work beyond different libraries and computing platforms. I'yard tired of looking upwards these different tools and their APIs then I decided to write downwards instructions for all of them in one place. Starting as a Stack Overflow answer here and expanded into this postal service, I've written an overview of the Parquet format plus a guide and cheatsheet for the Pythonic tools that utilise Parquet then that I (and hopefully you) never have to wait for them ever again.
Parquet format is optimized in three master means: columnar storage , columnar compression and data partitioning . The 4th style is past row groups , simply I won't cover those today as most tools don't support associating keys with particular row groups without some hacking. Below I go over each of these optimizations and then show you how to have advantage of each of them using the pop Pythonic information tools.
Column-Oriented Storage and Compression
Human being readable data formats similar CSV, JSON also as near common transactional SQL databases are stored in rows. As y'all scroll down lines in a row-oriented file the columns are laid out in a format-specific way across the line. Text compresses quite well these days, so yous can get away with quite a lot of computing using these formats. At some point, however, every bit the size of your data enters the gigabyte range loading and writing information on a single motorcar grind to a halt and take forever. This becomes a major hindrance to data science and motorcar learning engineering science, which is inherently iterative. Long iteration fourth dimension is a first-order roadblock to the efficient developer. Something must exist done!
Enter column-oriented information formats. These formats shop each column of data together and can load them one at a time. This leads to two performance optimizations:
- You only pay for the columns you load. This is called columnar storage.
Permit
mbe the total number of columns in a file andnbe the number of columns requested by the user. Loadingdue northcolumns results in merelynorthward/yardraw I/O volume. - The similarity of values within separate columns results in more than efficient compression. This is called columnar compression.
Note the
event_typecolumn in both row and column-oriented formats in the diagram beneath. A pinch algorithm volition have a much easier fourth dimension compressing repeats of the valuepartyin this cavalcade if they make up the entire value for that row, as in the column-oriented format. By contrast, the row-oriented format requires the compression algorithm to effigy out repeats occur at some offset in the row which volition vary based on the values in the previous columns. This is a much more difficult task.
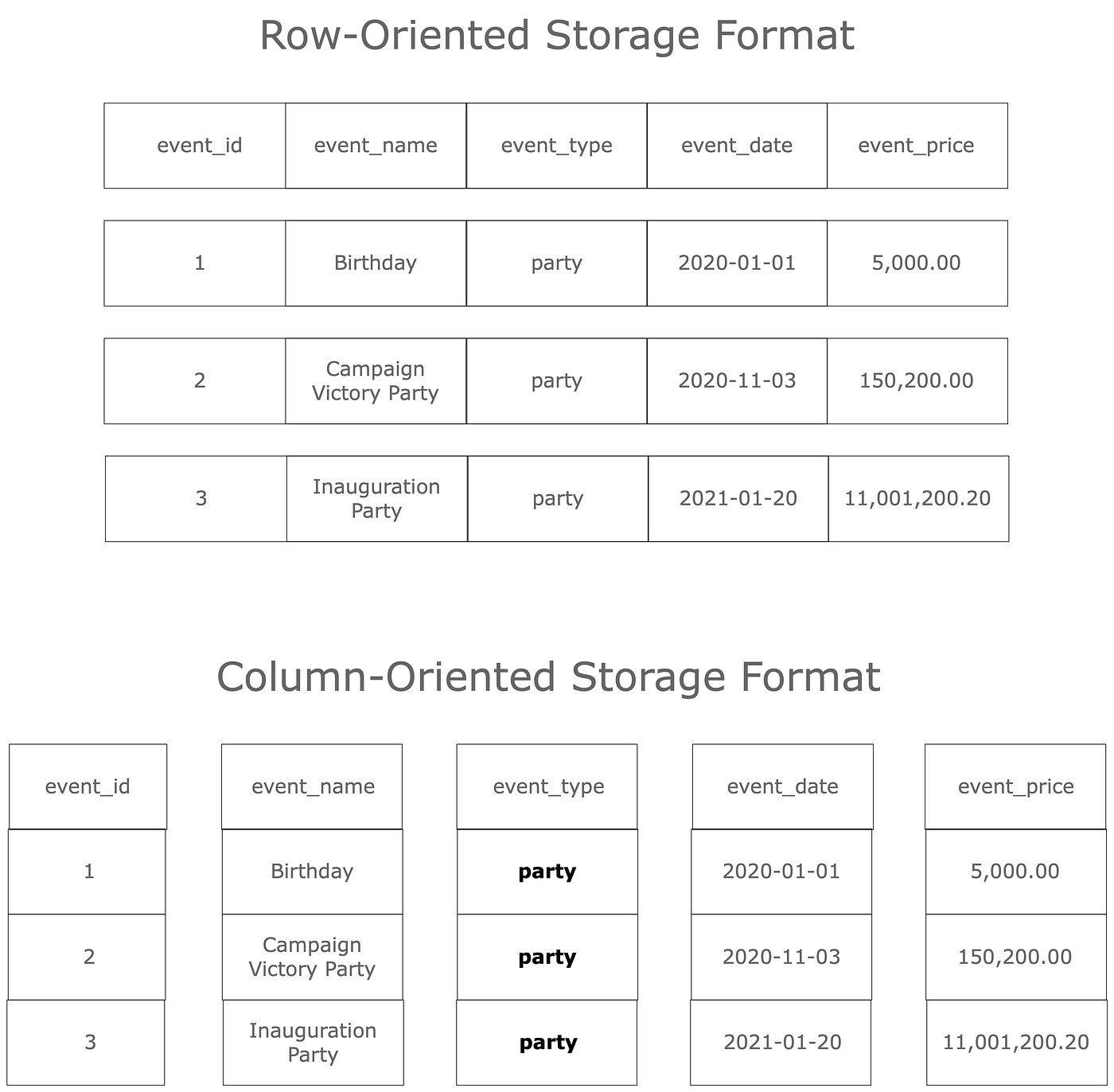
Columnar storage combines with columnar compression to produce dramatic performance improvements for most applications that do not require every cavalcade in the file. I accept often used PySpark to load CSV or JSON data that took a long time to load and converted it to Parquet format, afterward which using it with PySpark or even on a unmarried computer in Pandas became quick and painless.
Columnar Partitioning
The other way Parquet makes information more efficient is by segmentation data on the unique values within one or more columns. Each unique value in a column-wise partitioning scheme is called a key. Using a format originally defined by Apache Hive, one folder is created for each key, with boosted keys stored in sub-folders. This is chosen columnar partitioning , and information technology combines with columnar storage and columnar compression to dramatically improve I/O operation when loading part of a dataset corresponding to a partition key.
A Parquet dataset partitioned on gender and country would wait like this:
path
└── to
└── table
├── gender=male
│ ├── …
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── state=CN
│ │ └── information.parquet
│ └── … Each unique value for the columns gender and state gets a folder and sub-folder, respectively. The leaves of these division folder trees contain Parquet files using columnar storage and columnar compression, so any comeback in efficiency is on top of those optimizations!
Columnar partitioning optimizes loading data in the following style:
- Let
lbe all keys within a column. Letthoube the number of keys of interest. Loadingkkeys results in butchiliad/50raw I/O volume.
Row Group Partitioning
There is as well row group division if you demand to further logically partition your data, only most tools simply support specifying row grouping size and you take to practise the `cardinal →row group` lookup yourself. This limits its use. I recently used financial information that partitioned individual assets past their identifiers using row groups, but since the tools don't support this it was painful to load multiple keys as you had to manually parse the Parquet metadata to match the key to its respective row group.
For more than information on how the Parquet format works, check out the excellent PySpark Parquet documentation.
Parquet Partitions using Pandas & PyArrow
Pandas integrates with two libraries that support Parquet: PyArrow and fastparquet. They are specified via the engine argument of pandas.read_parquet() and pandas.DataFrame.to_parquet().
To store certain columns of your pandas.DataFrame using information segmentation with Pandas and PyArrow, use the pinch='snappy', engine='pyarrow' and partition_cols=[] arguments. Snappy compression is needed if you want to suspend information.
df.to_parquet(
path='analytics',
engine='pyarrow',
compression='snappy',
partition_cols=['event_name', 'event_category']
) This lays the folder tree and files like and then:
analytics.xxx/event_name=SomeEvent/event_category=SomeCategory/part-1.snappy.parquet
analytics.30/event_name=SomeEvent/event_category=OtherCategory/part-1.snappy.parquet
analytics.thirty/event_name=OtherEvent/event_category=SomeCategory/office-1.snappy.parquet
analytics/event_name=OtherEvent/event_category=OtherCategory/part-one.snappy.parquet Now that the Parquet files are laid out in this way, we can use partition column keys in a filter to limit the information we load. The pandas.read_parquet() method accepts engine, columns and filters arguments. The columns statement takes advantage of columnar storage and cavalcade compression, loading only the files respective to those columns nosotros ask for in an efficient fashion. The filters argument takes advantage of data partitioning by limiting the data loaded to sure folders corresponding to one or more keys in a partition cavalcade. Below we load the compressed event_name and other_column columns from the event_name partitioning folder SomeEvent.
df = pd.read_parquet(
path='analytics',
engine='pyarrow',
columns=['event_name', 'other_column'],
filters=[('event_name', '=', 'SomeEvent')]
) Reading Parquet Partitions using PyArrow
PyArrow has its ain API yous can use directly, which is a skillful thought if using Pandas directly results in errors. To load records from a ane or more partitions of a Parquet dataset using PyArrow based on their partition keys, we create an instance of the pyarrow.parquet.ParquetDataset using the filters statement with a tuple filter inside of a listing (more than on this below).
ParquetDatasets beget Tables which beget pandas.DataFrames. To convert certain columns of this ParquetDataset into a pyarrow.Table we utilize ParquetDataset.to_table(columns=[]). to_table() gets its arguments from the browse() method. This is followed by to_pandas() to create a pandas.DataFrame. Don't worry, the I/O only happens lazily at the end.
Here we load the columns event_name and other_column from within the Parquet partitioning on S3 corresponding to the event_name value of SomeEvent from the analytics. Both to_table() and to_pandas() accept a use_threads parameter yous should use to accelerate operation.
import pyarrow.parquet as pq
import s3fs fs = s3fs.S3FileSystem() dataset = pq.ParquetDataset(
's3://analytics',
filesystem=fs,
filters=[('event_name', '=', 'SomeEvent')],
use_threads=True
)
df = dataset.to_table(
columns=['event_name', 'other_column'],
use_threads=Truthful
).to_pandas()
You tin can come across that the use of threads every bit above results in many threads reading from S3 concurrently to my home network beneath.
You tin load a unmarried file or local folder direct into apyarrow.Table using pyarrow.parquet.read_table(), just this doesn't support S3 yet.
import pyarrow.parquet as pq df = pq.read_table(
path='analytics.parquet',
columns=['event_name', 'other_column']
).to_pandas()
PyArrow Boolean Partition Filtering
The documentation for partition filtering via the filters argument below is rather complicated, only it boils down to this: nest tuples within a listing for OR and within an outer list for AND.
filters (List[Tuple] or List[Listing[Tuple]] or None (default)) Rows which practice non match the filter predicate will be removed from scanned data. Partition keys embedded in a nested directory structure will exist exploited to avoid loading files at all if they comprise no matching rows. If use_legacy_dataset is True, filters tin can only reference sectionalisation keys and simply a hive-style directory structure is supported. When setting use_legacy_dataset to False, too within-file level filtering and different sectionalisation schemes are supported. Predicates are expressed in disjunctive normal class (DNF), similar [[('10', '=', 0), ...], ...]. DNF allows arbitrary boolean logical combinations of single column predicates. The innermost tuples each describe a single column predicate. The list of inner predicates is interpreted as a conjunction (AND), forming a more selective and multiple column predicate. Finally, the most outer list combines these filters as a disjunction (OR). Predicates may also be passed as List[Tuple]. This class is interpreted as a single conjunction. To express OR in predicates, one must use the (preferred) List[List[Tuple]] notation.
To utilize both partition keys to take hold of records respective to the event_name key SomeEvent and its sub-segmentation event_category key SomeCategory we utilize boolean AND logic - a single list of two filter tuples.
dataset = pq.ParquetDataset(
's3://analytics',
filesystem=fs,
filters=[
('event_name', '=', 'SomeEvent'),
('event_category', '=', 'SomeCategory')
]
)
df = dataset.to_table(
columns=['event_name', 'other_column']
).to_pandas() To load records from both the SomeEvent and OtherEvent keys of the event_name sectionalization nosotros apply boolean OR logic - nesting the filter tuples in their own AND inner lists within an outer OR listing.
dataset = pq.ParquetDataset(
's3://analytics',
filesystem=fs,
validate_schema=False,
filters=[
[('event_name', '=', 'SomeEvent')],
[('event_name', '=', 'OtherEvent')]
]
)
df = dataset.to_table(
columns=['event_name', 'other_column']
).to_pandas() Writing Parquet Datasets with PyArrow
PyArrow writes Parquet datasets using pyarrow.parquet.write_table().
import pyarrow
import pyarrow.parquet as pq table = pyarrow.Table.from_pandas(df)
pq.write_to_dataset(
tabular array,
'analytics',
partition_cols=['event_name', 'other_column'],
use_legacy_dataset=False
)
For writing Parquet datasets to Amazon S3 with PyArrow you need to use the s3fs package class s3fs.S3Filesystem (which you can configure with credentials via the key and secret options if you demand to, or it tin use ~/.aws/credentials):
import pyarrow
import pyarrow.parquet as pq
import s3fs s3 = s3fs.S3FileSystem() table = pyarrow.Tabular array.from_pandas(df)
pq.write_to_dataset(
table,
's3://analytics',
partition_cols=['event_name', 'other_column'],
use_legacy_dataset=False,
filesystem=s3
)
Parquet Partitions on S3 with AWS Data Wrangler
The easiest mode to piece of work with partitioned Parquet datasets on Amazon S3 using Pandas is with AWS Data Wrangler via the awswrangler PyPi package via the awswrangler.s3.to_parquet() and awswrangler.s3.read_parquet() methods. AWS provides excellent examples in this notebook. Note that Wrangler is powered by PyArrow, but offers a unproblematic interface with great features.
To write partitioned data to S3, set dataset=True and partition_columns=[]. You will want to set use_threads=Truthful to improve performance.
import awswrangler as wr wr.s3.to_parquet(
df=df,
path='s3://analytics',
dataset=True,
partition_cols=['event_name', 'event_category'],
use_threads=Truthful,
compression='snappy',
way='overwrite'
)
Reading Parquet data with sectionalization filtering works differently than with PyArrow. With awswrangler you use functions to filter to sure partition keys.
df = wr.s3.read_parquet(
path='s3://analytics',
dataset=True,
columns=['event_name', 'other_column'],
partition_filter=lambda x: ten['event_name'] == 'SomeEvent',
use_threads=True
) Annotation that in either method y'all can pass in your ain boto3_session if yous need to cosign or prepare other S3 options.
Parquet Partitions with Google Cloud Storage
As with AWS, panads.read_parquet() won't work with a parquet folder of 1 or more files (partitioned or not) on GCS.
import gcsfs
import pyarrow.parquet every bit pq # Add credentials or rely on gcloud CLI setup
gs = gcsfs.GCSFileSystem() ds = pq.ParquetDataset("gs://analytics", filesystem=gs) df = ds.read_pandas().to_pandas()
I had not washed this before and Deep Discovery is a cross-deject company on AWS and GCP, so shout outs to @LPillmann for creating a gist with the answer.
Parquet Partitions with fastparquet
Fastparquet is a Parquet library created by the people that brought us Dask, a wonderful distributed computing engine I'll talk near below. I hadn't used FastParquet directly earlier writing this post, and I was excited to try information technology. To write data from a pandas DataFrame in Parquet format, use fastparquet.write.
import fastparquet fastparquet.write(
df,
compression='SNAPPY',
partition_on=['event_name', 'event_category']
)
To load certain columns of a partitioned collection yous use fastparquet.ParquetFile and ParquetFile.to_pandas(). ParquetFile won't take a directory proper noun every bit the path argument then you will have to walk the directory path of your collection and excerpt all the Parquet filenames. Then y'all supply the root directory as an statement and FastParquet can read your segmentation scheme. Tuple filters piece of work just like PyArrow.
import os
from glob import glob
import fastparquet # Walk the directory and observe all the parquet files within
parquet_root = 'analytics'
parquet_files = [y for x in os.walk(parquet_root) for y in glob(os.path.bring together(10[0], '*.parquet'))] # The root statement lets it know where to look for partitions
pf = fastparquet.ParquetFile(parquet_files, root=parquet_root) # At present we convert to pd.DataFrame specifying columns and filters
df = pf.to_pandas(
columns=['event_name', 'other_column'],
filters=('event_name', '=', 'SomeEvent')
)
That'southward it! Ultimately I couldn't get FastParquet to work because my data was laboriously compressed by PySpark using snappy compression, which fastparquet does not support reading. I've no doubt information technology works, however, as I've used it many times in Pandas via the engine='fastparquet' argument whenever the PyArrow engine has a issues :)
Parquet Partitions with PySpark
At that place is a hard limit to the size of data you can process on one machine using Pandas. Across that limit you're looking at using tools like PySpark or Dask. As a Hadoop evangelist I learned to recall in map/reduce/iterate and I'1000 fluent in PySpark, so I use it often. PySpark uses the pyspark.sql.DataFrame API to work with Parquet datasets. To create a partitioned Parquet dataset from a DataFrame utilize the pyspark.sql.DataFrameWriter class normally accessed via a DataFrame's write property via the parquet() method and its partitionBy=[] argument.
df.write.mode('overwrite').parquet(
path='s3://analytics',
partitionBy=['event_type', 'event_category'],
compression='snappy'
) To read this partitioned Parquet dataset back in PySpark use pyspark.sql.DataFrameReader.read_parquet(), unremarkably accessed via the SparkSession.read holding. Chain the pyspark.sql.DataFrame.select() method to select certain columns and the pyspark.sql.DataFrame.filter() method to filter to certain partitions.
import pyspark.sql.functions every bit F
from pyspark.sql import SparkSession spark = SparkSession \
.architect \
.appName('Analytics Application') \
.getOrCreate() df = spark.read.parquet('s3://analytics') \
.select('event_type', 'other_column') \
.filter(F.column('event_type') == 'SomeEvent')
Yous don't need to tell Spark annihilation about Parquet optimizations, it just figures out how to take advantage of columnar storage, columnar compression and data sectionalisation all on its own. Pretty cool, eh?
Parquet Partitions with Dask
Dask is the distributed computing framework for Python you'll want to employ if you need to move around numpy.arrays — which happens a lot in machine learning or GPU computing in general (run across: RAPIDS). This is something that PySpark but cannot do and the reason it has its own contained toolset for anything to practise with machine learning. To prefer PySpark for your car learning pipelines y'all accept to adopt Spark ML (MLlib). Not so for Dask! You can apply the standard Python tools. Before I institute HuggingFace Tokenizers (which is so fast one Rust pid volition do) I used Dask to tokenize data in parallel. I've also used it in search applications for bulk encoding documents in a large corpus using fine-tuned BERT and Judgement-BERT models.
I struggled with Dask during the early days, merely I've come to love information technology since I started running my own workers (you shouldn't have to, I started out in QA automation and consequently break things at an alarming rate). If you're using Dask it is probably to use i or more than machines to process datasets in parallel, then you lot'll want to load Parquet files with Dask'due south own APIs rather than using Pandas and then converting to a dask.dataframe.DataFrame.
In that location are excellent docs on reading and writing Dask DataFrames. Yous do so via dask.dataframe.read_parquet() and dask.dataframe.to_parquet(). To read a Dask DataFrame from Amazon S3, supply the path, a lambda filter, whatsoever storage options and the number of threads to utilize. You can pick betwixt fastparquet and PyArrow engines. read_parquet() returns every bit many partitions as there are Parquet files, so go on in mind that you may demand to repartition() once you load to make use of all your computer(s)' cores.
import dask.dataframe as dd
import s3fs
from dask.distributed import Client customer = Client('127.0.0.one:8786') # Setup AWS configuration and credentials
storage_options = {
"client_kwargs": {
"region_name": "united states of america-eastward-1",
},
"fundamental": aws_access_key_id,
"secret": aws_secret_access_key
} ddf = dask.dataframe.read_parquet(
path='s3://analytics',
columns=['event_name', 'other_column'],
filter=lambda x: x['event_name'] in TICKERS,
storage_options=storage_options,
engine='pyarrow',
nthreads=viii,
)
To write immediately write a Dask DataFrame to partitioned Parquet format dask.dataframe.to_parquet(). Note that Dask will write ane file per partition, and so over again yous may want to repartition() to as many files every bit you'd like to read in parallel, keeping in listen how many partition keys your partition columns have every bit each volition have its own directory.
import dask.dataframe equally dd
import s3fs dask.dataframe.to_parquet(
ddf,
's3://analytics',
compression='snappy',
partition_on=['event_name', 'event_type'],
compute=Truthful,
)
Determination
Whew, that's it! Nosotros've covered all the ways you can read and write Parquet datasets in Python using columnar storage, columnar compression and data division. Used together, these iii optimizations provide near random access of data, which can dramatically improve access speeds.
Hopefully this helps you work with Parquet to exist much more productive :) If no 1 else reads this post, I know that I will numerous times over the years as I cantankerous APIs and get mixed up about APIs and syntax.
Hey, rent me. I gotta consume!

My proper noun is Russell Jurney, and I'm a auto learning engineer. I dearest to write about what I practice and equally a consultant, I hope that yous'll read my posts and think of me when you demand aid with a project. I have extensive feel with Python for car learning and big datasets and have setup machine learning operations for entire companies. I've built a number of AI systems and applications over the last decade individually or as part of a squad. I've gotten good at information technology. Give me a shout if yous need advice or assistance in building AI at rjurney@datasyndrome.com. I hope y'all enjoyed the postal service!
Source: https://blog.datasyndrome.com/python-and-parquet-performance-e71da65269ce
0 Response to "How to Read a Parquet File From S3 Using Python"
Post a Comment